OLAP é um conceito de interface com o usuário que proporciona a capacidade de ter idéias sobre os dados, permitindo analisá-los profundamente em diversos ângulos. As funções básicas são:
- Visualização multidimensional dos dados;
- Exploração;
- Rotação;
- Vários modos de visualização.
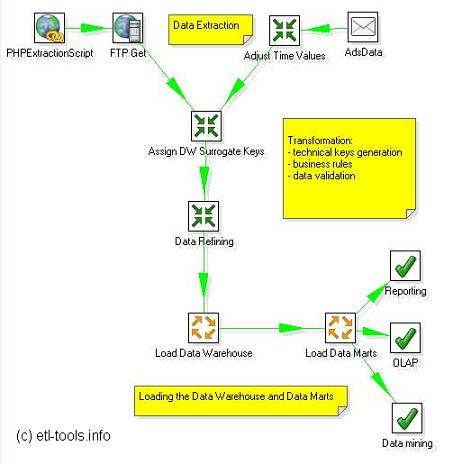
O OLAP e o Data Warehouse são destinados a trabalharem juntos. Enquanto o DW armazena as informações de forma eficiente, o OLAP deve recuperá-las com a mesma eficiência, porém com muita rapidez.
O OLAP é uma interface com o usuário e não uma forma de armazenamento de dados, porém se utiliza do armazenamento para poder apresentar as informações. Os métodos de armazenamento são:
- ROLAP (OLAP Relacional): Os dados são armazenados de forma relacional.
- MOLAP (OLAP Multidimensional): Os dados são armazenados de forma multidimensional.
- HOLAP (OLAP Híbrido): Uma combinação dos métodos ROLAP e MOLAP.
- DOLAP (OLAP Desktop): O conjunto de dados multidimensionais deve ser criado no servidor e transferido para o desktop. Permite portabilidade aos usuários OLAP que não possuem acesso direto ao servidor.
Os métodos mais comuns de armazenamento de dados utilizados pelos sistemas OLAP são ROLAP e MOLAP, a única diferença entre eles é a tecnologia de banco de dados. O ROLAP usa a tecnologia RDBMS (Relational DataBase Management System), na qual os dados são armazenados em uma série de tabelas e colunas. Enquanto o MOLAP usa a tecnologia MDDB (MultiDimensional Database), onde os dados são armazenados em arrays multidimensionais.
ROLAP é mais indicado para DATA WAREHOUSE pelo grande volume de dados, a necessidade de um maior número de funções e diversas regras de negócio a serem aplicadas. Responde às consultas da mesma forma que os aplicativos RDBMSs, a velocidade da resposta depende da informação desejada, pois a maior parte do processamento é feito em tempo de execução tendo em vista que os dados pré-calculados e resumidos geralmente não atendem a todas as solicitações dos usuários.
MOLAP é mais indidado para DATA MARTS, onde os dados são mais específicos e o aplicativo será direcionado na análise com dimensionalidade limitada e pouco detalhamento das informações fornecendo uma resposta rápida para praticamente qualquer consulta, pois no modelo multidimensional são gerados previamente todas as combinações e resumos possíveis.
fonte: http://www.devmedia.com.br/conceitos-basicos-sobre-olap/12523